浏览器相关
... 2022-12-23 About 12 min
# 浏览器相关
# 页面的渲染顺序、展示顺序
# DOM 和 BOM 的区别
dom 是文档对象模型,dom 是为了操作文档出现的 API,document 是其的一个对象,dom 和文档有关,此处的文档指的是网页,也就是 html 文档,dom 和浏览器无关,他关注的是网页本身的内容
bom 是浏览器的对象模型,bom 是为了操作浏览器出现的 API,window 是其的一个对象,window 对象即为 js 访问浏览器的 API,同时在 ECMAScript 中充当 Global 对象
# reflow 和 repaint
reflow:当涉及到 dom 节点的布局属性发生变化时候,就会重新计算属性,浏览器会重新描绘相应的元素,此过程叫做 reflow(回流或重排)
repaint:当影响 dom 元素的可见性的属性发生变化的时候(eg:color、font),浏览器会重新描绘相应的元素,此过程叫做 repaint(重绘),因此重排必然会引起重绘
eg: 会引起 reflow 和 repaint 的一些操作
- 窗口大小变化
- 字体大小变化
- 样式表变化
- 元素内容变化,尤其是输入控件
- css 伪类变化,在交互中是必然会发生
- 所有的 dom 操作
- width、clientWidth、scrollTop 等布局高度的重新计算
如何在研发的过程注意这些点
不要逐条行内样式修改,使用 className
避免频繁操作 dom 特别是在 jq 时代
不要频繁读取元素的集合属性,但是如果交互确实需要去做的时候也没有办法(我自己认为的哈)
绝对定位的脱离文档流,避免引起父元素以及后续元素大量的回流(特别在元素的拖动中)
# iframe 框架优缺点
优点:
iframe 能够 100%保证嵌入的网页展示
如果多个网页引入 iframe,那么你只需要修改 iframe 的内容,就可以实现调用的每一个页面内容的修改,方便快捷(有点组件的感觉哈)
组件化的使用,头部和尾部的使用
遇到第三方插件加载缓慢的时候可以使用 iframe
缺点:
搜索引擎无法解读 iframe 里面的页面内容
滚动条的混乱
使用框架架构时,保证正确的导航链接
iframe 页面会增加服务器的 http 请求
使用 iframe 怎么说呢?我一般是能不用就不用的,但是有些时候又是必须要去使用的
注意点,如果本身懂的比较深的微前端的知识,可以往微前端上面去回答,可以对这个问题加分,如果知识知道一点皮毛可以不去做往深处引
# 事件委托
事件委托利用了事件冒泡,只指定一个事件处理程序,就可以管理某一类型的所有事件。所有用到按钮的事件(多数鼠标事件和键盘事件)都适合采用事件委托技术, 使用事件委托可以节省内存。
实现的时候通过监听父级的时间来操作子级
# cookie、localStorage、sessionStorage 区别
| 特性 | cookie | localStorage | sessionStorage |
|---|---|---|---|
| 由谁初始化 | 客户端或服务器,服务器可以使用 Set-Cookie 请求头。 | 客户端 | 客户端 |
| 数据的生命周期 | 一般由服务器生成,可设置失效时间,如果在浏览器生成,默认是关闭浏览器之后失效 | 永久保存,可清除 | 仅在当前会话有效,关闭页面后清除 |
| 存放数据大小 | 4KB | 5MB | 5MB |
| 与服务器通信 | 每次都会携带在 HTTP 头中,如果使用 cookie 保存过多数据会带来性能问题 | 仅在客户端保存 | 仅在客户端保存 |
| 用途 | 一般由服务器生成,用于标识用户身份 | 用于浏览器缓存数据 | 用于浏览器缓存数据 |
| 访问权限 | 任意窗口 | 任意窗口 | 当前页面窗口 |
# 同源策略
同源策略可防止 js 发生跨域请求,源被定义为 URI,主机名和端口号的组合。此策略可防止页面的恶意脚本通过该页面的文档对象模型,访问另一个网页上的敏感数据
同源策略是浏览器行为,目的是为了浏览器的安全问题
# 如何理解面向对象,以及如何理解函数式编程
# 浏览器的渲染过程
- DNS 的查询(也就是根据域名去找对应的 ip 地址)
- TCP 的连接(连接建立、数据传送以及连接释放)
- HTTP 请求即响应
- 服务端响应
- 客户端渲染
渲染过程如下:
- 解析 html 生成 dom 树
- 解析 css 生成 cssom 树
- 将 dom 树和 cssom 树规则合并在一起生成渲染树
- 遍历渲染树开始布局,计算每一个节点的位置信息等
- 将渲染树每个节点绘制到屏幕
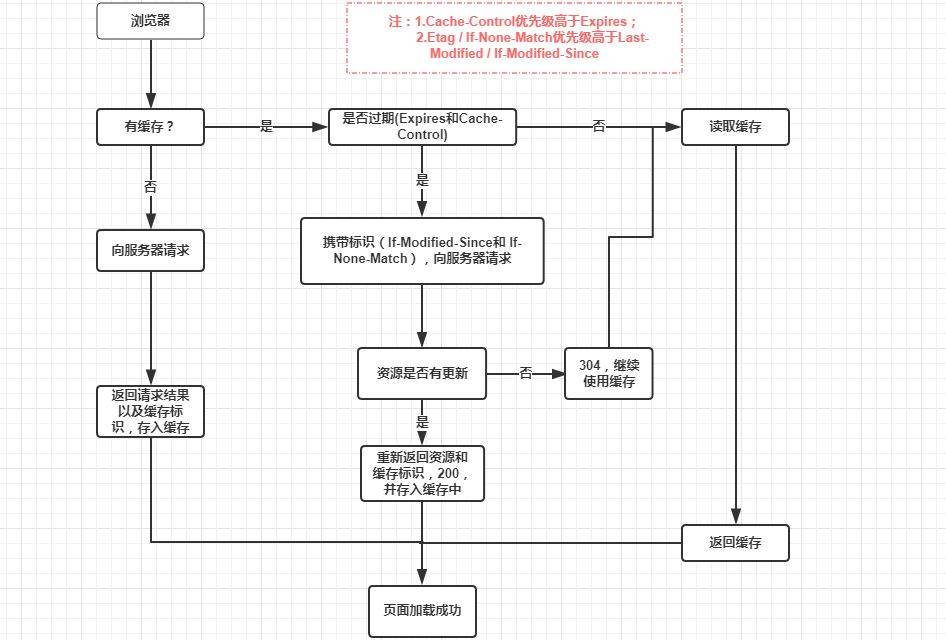
# 浏览器的缓存机制
浏览器的缓存机制也就是我们说的 HTTP 缓存机制,其机制是根据 HTTP 抱文的缓存标识进行的,HTTP 抱文分为两种:
- HTTP 请求(Request)抱文
- HTTP 响应(Response)抱文
浏览器与服务器通信的方式为应答模式,即为:浏览器发起 HTTP 请求 – 服务器响应该请求,那么浏览器第一次向服务器发起该请求后拿到请求结果,会根据响应报文中 HTTP 头的缓存标识,决定是否缓存结果,是则将请求结果和缓存标识存入浏览器缓存中
- 浏览器每次发起请求,都会先在浏览器缓存中查找该请求的结果以及缓存标识
- 浏览器每次拿到返回的请求结果都会将该结果和缓存标识存入浏览器缓存中
缓存分为强制缓存和协商缓存
强制缓存
- HTTP 响应报文中的 expires--
expires: Wed, 21 Oct 2020 03:25:41 GMT,这个是一个绝对时间,在指定的时间前请求缓存生效 - HTTP 响应报文中的 Cache-Control--
cache-control: max-age=600,这是一个相对值,单位 s,也就是 600s 之内再次请求会直接使用缓存,强制缓存生效在无法确定客户端的时间是否与服务端的时间同步的情况下,Cache-Control 相比于 expires 是更好的选择,所以同时存在时,只有 Cache-Control 生效
强制缓存的返回状态码为: 200
但是看返回值中的 size 栏中有
from memory cache和from disk cache:分别是内存中的缓存和硬盘中的缓存,浏览器对与两者的读取顺序是: memory -> disk内存缓存:快速读取(直接写入进程的内存中,方便下次使用和快速读取)和时效性(也就是一旦关闭进程关闭,内存就会清空)
直接将缓存写入硬盘文件中,读取缓存需要对硬盘文件进行 I/O 操作,读取是复杂的,速度也是比内存慢的
- HTTP 响应报文中的 expires--
协商缓存(协商缓存就是强制缓存失效后,浏览器携带缓存标识向服务器发起请求,由服务器根据缓存标识决定是否使用缓存的过程)
- 协商缓存生效,返回 304
- 协商缓存失效,返回 200 和请求结果结果
协商缓存的表示在响应的报文中为:Last-Modified / If-Modified-Since 和 Etag / If-None-Match, 其中 Etag / If-None-Match > Last-Modified / If-Modified-Since
- 也就是说: 强制缓存优先于协商缓存进行,若强制缓存(Expires 和 Cache-Control)生效则直接使用缓存,若不生效则进行协商缓存(Last-Modified / If-Modified-Since 和 Etag / If-None-Match),协商缓存由服务器决定是否使用缓存,若协商缓存失效,那么代表该请求的缓存失效,重新获取请求结果,再存入浏览器缓存中;生效则返回 304,继续使用缓存
# 浏览器的垃圾回收机制与内存泄漏
浏览器对 js 具有自动垃圾回收机制(GC: Garbage COllecation),也就是说,执行环境会负责管理代码执行过程中使用的内存,其原理:垃圾收集器会定期(周期性)找出那些不再继续使用的变量,然后释放其内存。但是这个过程不是实时的,因为其开销比较大并且 GC 时停止响应其他操作,所以垃圾回收器会按照固定的时间间隔周期性的执行。
两种实现方式:标记清除和引用计数。引用计数不太常用,标记清除较为常用。
# 1. 标记清除
js 中最常用的垃圾回收方式就是标记清除。当变量进入环境时,变量“进入环境”,被标记,离开环境时,被回收
垃圾回收器在运行的时候会给存储在内存中的所有变量都加上标记,然后它会去掉环境中的变量以及被环境中的变量引用的变量的标记(闭包),而在此之后再被加上标记的变量将被视为准备删除的变量,原因是环境中的变量已经无法访问到这些变量了。最后垃圾回收器完成内存清除工作,销毁那些带标记的值并回收它们所占用的内存空间。 到目前为止,IE9+、Firefox、Opera、Chrome、Safari 的 js 实现使用的都是标记清除的垃圾回收策略或类似的策略,只不过垃圾收集的时间间隔互不相同。
# 2. 引用计数
引用计数的含义是跟踪记录每个值被引用的次数。当声明了一个变量并将一个引用类型值赋给该变量时,则这个值的引用次数就是 1。如果同一个值又被赋给另一个变量,则该值的引用次数加 1。相反,如果包含对这个值引用的变量又取得了另外一个值,则这个值的引用次数减 1。当这个值的引用次数变成 0 时,则说明没有办法再访问这个值了,因而就可以将其占用的内存空间回收回来。这样,当垃圾回收器下次再运行时,它就会释放那些引用次数为 0 的值所占用的内存。
function test() {
var a = {}; //a的引用次数为0
var b = a; //a的引用次数加1,为1
var c = a; //a的引用次数再加1,为2
var b = {}; //a的引用次数减1,为1
}
1
2
3
4
5
6
2
3
4
5
6
使用这种方法看起来好像很好理解,但当遇到循环引用的时候就很难受了
var element = document.getElementById("some_element");
var myObject = new Object();
myObject.e = element;
element.o = myObject;
1
2
3
4
2
3
4
window.onload = function outerFunction() {
var obj = document.getElementById("element");
obj.onclick = function innerFunction() {};
};
1
2
3
4
2
3
4
第二个例子:obj 引用了 document.getElementById('element'),onclick 方法会引用外部环境中的变量,自然也包括 obj,这种隐蔽的循环引用很难发现的
遇到这样的情况我们需要手动去解除
myObject.element = null;
element.o = null;
window.onload = function outerFunction() {
var obj = document.getElementById("element");
obj.onclick = function innerFunction() {};
obj = null;
};
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
在 IE8-格外需要注意这些事情,不过现在我们开发需要兼容 IE8-的情况正在一步步减少
# 内存管理
- 何时触发垃圾回收?
垃圾回收器周期性运行,如果分配的内存非常多,那么回收工作也会很艰巨,确定垃圾回收时间间隔就变成了一个值得思考的问题。IE6 的垃圾回收是根据内存分配量运行的,当环境中存在 256 个变量、4096 个对象、64k 的字符串任意一种情况的时候就会触发垃圾回收器工作,看起来很科学,不用按一段时间就调用一次,有时候会没必要,这样按需调用不是很好吗?但是如果环境中就是有这么多变量等一直存在,现在脚本如此复杂,很正常,那么结果就是垃圾回收器一直在工作,这样浏览器就没法儿玩儿了。
微软在 IE7 中做了调整,触发条件不再是固定的,而是动态修改的,初始值和 IE6 相同,如果垃圾回收器回收的内存分配量低于程序占用内存的 15%,说明大部分内存不可被回收,设的垃圾回收触发条件过于敏感,这时候把临街条件翻倍,如果回收的内存高于 85%,说明大部分内存早就该清理了,这时候把触发条件置回。这样就使垃圾回收工作职能了很多
- 合理的 GC 方案
基本方案 Javascript 引擎基础 GC 方案是(simple GC):mark and sweep(标记清除),即:
- 遍历所有可访问的对象。
- 回收已不可访问的对象。
GC 缺陷 和其他语言一样,javascript 的 GC 策略也无法避免一个问题:GC 时,停止响应其他操作,这是为了安全考虑。而 Javascript 的 GC 在 100ms 甚至以上,对一般的应用还好,但对于 JS 游戏,动画对连贯性要求比较高的应用,就麻烦了。这就是新引擎需要优化的点:避免 GC 造成的长时间停止响应。
GC 优化策略
- 分代回收:区分“临时”与“持久”对象,多回收“临时对象”区(young generation),少回收“持久对象”区(tenured generation),减少每次需要遍历的对象
- 增量 GC:增加回收次数,牺牲的是中断次数